
Learn about the Key Parameters to ensure your digital product’s Audio Quality
Do you know the differences between formats and how compression rates work? Learn about these and other parameters in the article!


Audio quality for recorders or interfaces can be quite confusing. But if you’re going to work with videos or podcasts, you better know how to interpret these parameters when recording or exporting files, whether on Audacity (free), Reaper, Adobe Audition or even on video editors.
In this article, we’re going to talk about the differences between sample rates, bit depth, file compression rates and format variations. Thus, you’ll be more confident about your choices regarding audio quality and ensure good results.
In short, you’ll understand why we recommend recording in an uncompressed format (WAV, for example) at 24 bits and 48 kHz. In addition, you’ll also know why in most cases we won’t need more than an MP3 format with 192 kbps to export audio with excellent quality.
We’ll also talk about the possibility of higher compression to podcast files, which can be created in mono MP3 format with 64 kbps, facilitating online access.
Formats, extensions, and codecs: What do they mean?
When referring to audio files we use terms such as formats, extensions and codecs. In a simple explanation, format is merely the type of file, identified in its extension (*.mp3, *.wav, *.ogg, *.wma, etc.), which usually tells us how the file was encoded, or its codec.
For example, a file in MP3 format has a *.mp3 extension and MPEG-1 Audio Layer III codec.
Examples of audio file extensions
These extensions get mixed up, but the important thing to know is that, just like videos, files with the same type of extension don’t always have the same codec and vice versa.
This information is valid so you don’t get lost if you don’t understand why the software you usually use to play your *.m4a files suddenly refuses so play another one with same extension, for example.
This situation may indicate that the codecs used were different. In this case, the solution would be to use other software to read the file or perform a conversion (new encoding), which can be performed in video editors.
These format and codec variations depend on choices from the companies that develop the software that run the files. This is where many things come into play, such as technical specifications and even relationships with patents.
As to the files, they are usually divided into two types: uncompressed or compressed.
Uncompressed files
Dedicated audio recording equipment usually give us options for recording files without any loss of information. These uncompressed files can be created in several formats and extensions, such as WAV, AIFF, FLAC and ALAC. For those who are familiar with photography, they are equivalent to RAW or DNG.
Since the files are usually quite large, the use of these lossless formats in the final product is only recommended in certain cases, such as:
- When the final product can be processed by consumers (files used in audio banks, for example);
- When it’s intended for physical media (CD, DVD e Blue-Ray); or
- For the audiophile market (due to perceived value and to ensure high quality).
However, even if you’re not interested in finishing the process as a WAV (one of the most common), lossless formats can be quite useful during the editing step. Because they hold a lot of information, they support more extreme changes without audio loss.
Thus, by using plugins, conversions, and processing, you can manipulate them more freely, ensuring excellent quality, even if a compressed file is generated afterwards.
Compressed files
Most of the equipment available on the market (cameras, cellphones and even audio recorders) usually deliver files already compressed. These files are more convenient, easy to process and require less storage space, having very small file sizes (in bytes).
Some examples of these formats are: 3GP, AAC, M4A, OGG, WMA and MP3, which is without a doubt the best known. These files are what JPEG or GIF formats are to images.
Through a complex algorithm, such files are created by maintaining only the information that is relevant to our ears. Depending on the compression mode, we can generate an MP3 from a WAV file and have a file that is 10 times smaller, without perceptible changes to the sound.
Size comparison between MP3 and Wave
Speaking of MP3, despite its great popularity, this format is currently considered obsolete, since others, such as ACC (.acc or .m4a extensions) allow for even smaller files with better quality.
Still, MP3 continues to be widely used because most of the software and equipment were developed for this format. While talking about compression rates we’ll use it as an example.
Compression rate: What is its relationship with audio quality?
Now that you understand that a file can be compressed and still maintain enough quality for our ears, you need to know that this compression level can vary greatly.
It’s through the compression rate value (or bitrate) that we can control the file size and consequently, audio quality.
For example, a 320 kbps MP3 (kilobits per second) can sound as good as an uncompressed CD or DVD audio. As the bitrate value lowers, the file becomes smaller, but audio loss becomes perceptible, depending on the audio in questions.
Winamp player show an MP3 compression rate
Just to give you an idea of how this rate affects audio quality, check out the references below:
- 320 kbps – audio indistinguishable from CD quality;
- 192 kbps – no significant loss for most people;
- 128 kbps – slightly perceptible loss;
- 96 kbps – quality similar to FM radio;
- 32 kbps – similar to AM radio;
- 16 kbps – similar to shortwave radio (e.g. walkie-talkies).
Remembering that the values and descriptions above are only an approximation, because file compression acts differently for each type of audio. The more perceptible information (or the more complex for the audio in question), the more margin there is for the compression to affect quality.
This is why there may be no problem if you generate a file with only a 64 kbps, mono file – with a single audio signal playing simultaneously on both left (L) and right (R) channels, for a podcast without a soundtrack.
However, a song that is well produced in a studio, with many different instruments, can suffer perceptible loss even if the compressed file is 128 kpbs, stereo – with a different signal for each speaker, right and left.
We are talking here about fixed compression rates (CBR – constant bitrate), but there is also the possibility of generating files with variable rates, called VBRs (variable bitrate) or ABRs (average bitrate).
In VBRs, the algorithm analyzes the audio and decides which parts can be compressed more aggressively and which parts less information can be removed. ABRs behave in a similar manner, but they keep the average of the rate stipulated previously. These two methods, although smarter, may create incompatibilities with certain players.
When we talk about compression vs. quality, remember that there are no rules: each case is a case and you need to evaluate individually in order to know how acceptable the losses are, or if giving up on quality for the sake of convenience (faster download or less storage impact, for example) is worthwhile.
Remember that certain websites and services recode audio after they are uploaded. Since we have no control over this process, it may be a good idea to upload files with slightly higher quality than necessary to give you a safety margin in case of new conversions.
Amplitude bit depth: 16 bits or 24 bits?
If you’re going to use an audio interface/board or a dedicated recorded, you’ll come across bit depth settings. This is related to the PCM digital audio standard and does not apply to compressed files.
The values refer to the signal-to-noise ratio. In other words, it has to do with dynamics or volume levels that the file can register with quality.
It’s as if it were an amplitude bit depth of the sound. Thus, in theory, an audio with 16 bits can represent 65,536 levels of volume between the lowest and highest value of the scale. With 24 bits, there are 16.7 million levels.
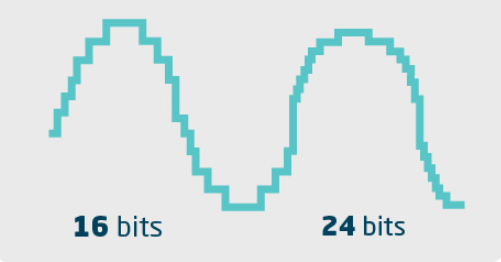
Illustrative representation of amplitude bit depth
Despite the large numerical disparity, in practice, there’s no perceptible variation to our ears. However, there’s a technical difference that can, in certain cases, give the 24-bit file an edge when capturing and editing.
We know that we have to be careful with the input level when recording, to prevent audio clipping. This is what happens when the graphic meter is too high, exceeding 0 dB (maximum value before overdrive/digital distortion occurs). Therefore, you should respect a certain safety margin called “headroom”.
Be extra careful with audio quality
At 16 bits, you need to pay attention so that the input level isn’t too low.
Since there isn’t sufficient bit depth to accurately register extremely weak signals, these audios might sound digitally distorted or contain noise, through a process called dithering, which seeks to mask these quantization flaws.
Thus, since a 16-bit file registers fewer volume gradations (48 dB less in comparison with 24 bits), theoretically you run the risk of, when increasing the software’s volume, you’ll encounter a higher amount of these “hisses”. Technically, at 24 bits you shouldn’t run this risk.
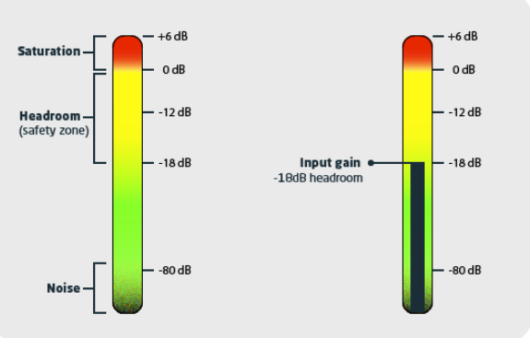
Illustrative representation of the audio graphic meter zones
However, you will certainly come across some noise (noise floor) from various sources, such as cables, electric power, preamps, microphones, low-quality components, “room noise” and even resulting from the natural operation of the equipment used (certain manufacturers even specify the value in the manual).
Thus, in practice, bit depth values probably won’t significantly influence your recording. So, if your equipment only supports 16 bits, relax, after all it’s the same bit depth value as an audio CD, which as you know, can deliver crystal clear audio for most uses.
Even though a 24-bit file isn’t much larger than at 16 bits, recording in this higher bit depth whenever possible is worth it. In addition to ensuring a higher safety margin when digitally processing the file, 24 bits is the DVD and Blu-Ray standard. This way you avoid unnecessary conversions if the final audio is stored on one of these physical forms.
Nowadays, there’s even equipment that work with 32 bits, but you’ll hardly benefit from such a bit rate.
This happens, for example, when the sound is created directly on a computer, without going through the entire analog paraphernalia, which adds noise to the process.
Sample rate: What does this value tell us?
Other values that you’ll come across are relative to sample rates. These numbers are relative to the number of times per second that the analog sound is “registered”, in order to be rebuilt digitally (44.1 kHz equals 44,100 samples per second). It’s as if it were the number of frames per second in videos, which are necessary for your eyes to create the illusion of movement.
These values also refer to the maximum frequency (sound with more treble) possible to be played on the file.
For clarity, you should remember that the more bass a sound has (low pitch), the lower is its frequency (measured in Hertz). The more treble the sound has (higher pitch), the higher the numerical value in Hz is.
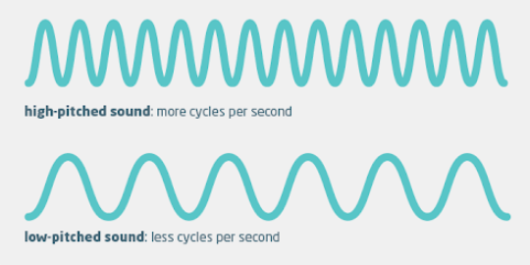
Representation of bass and treble frequencies
Overall, the lowest frequency we can hear – with more bass –, is around 20 Hz (or 20 wave oscillations per second); and the highest – with more treble –, around 20 kHz (or 20,000 oscillations per second).
For technical reasons (Nyquist’s theorem), digital media needs to hold twice the frequency capacity it’ll play. Therefore, the sample rate of a CD (a long-standing industry standard) was defined at 44.1 kHz.
This means that with this value there’s enough data (per second) to represent frequencies of up to 22 kHz approximately. In theory, this is more than needed in order to reproduce any sound that is audible for us, where many people cannot hear higher frequencies, especially with age – most adults can’t hear frequencies over 17 kHz or even 16 kHz.
Then, in 1995, DVDs hit the market, and the standard chosen became 48 kHz. Again, the number was established due to a technical issue: basically to round up values to the number of frames per second (fps) in video.
According to what we’ve seen earlier, it’s clear that this slight increase doesn’t change our perception of the sound played.
Nevertheless, certain equipment allows recordings of 96 kHz or more. The only reason to work with such high sample rate values is to have more data to manipulate files digitally (something similar to what we’ve seen about working with WAV in comparison to MP3 formats).
However, since this implies in more storage space and higher processing requirements, we don’t recommend it. For online videos or podcasts, the advantages will probably be insignificant. Additionally, in certain cases, higher sample rate values may create undesirable harmonic distortions.
Therefore, we recommend that you use 48 kHz, especially when working with video. Since it’s still the market standard, you run less risk of incompatibility or reading errors.
Some of the possible compatibility errors have to do with the duration of the audio and pitch reproduced. For example, a 44.1 kHz file might sound faster than with “treble” tones in a project configured for 48 kHz. On the other hand, a 48 kHz file, if read as 44.1 kHz, will sound slower with more “bass” tones.
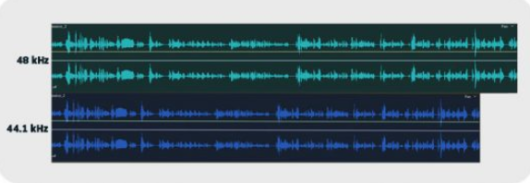
44.1 kHz and 48 kHz audios on the same timeline
Fortunately, most software nowadays can identify these sample rate differences and correctly interpret the file automatically, converting it instantly (usually followed by a warning) when the value doesn’t match the software’s value.
In certain cases, for those who work exclusively with audio (especially music), it might be a good idea to stick to 44.1 kHz, because although CDs are no longer used, they are still be main physical media for music consumption.
Actually, you’ll hardly have problems converting one standard into another. As we said earlier, nowadays the platforms and software read and interpret both sample rate values quite well.
These recommendations are merely an assurance against possible and rare problems, which can create slight errors (digital artifacts) resulting from conversion failures.
What you should consider when applying audio quality knowledge on a daily basis
Talking about audio settings, preferences, and recommendations requires certain observations. Since the mode of consumption varies greatly, as well as people’s hearing capacity, which can be an excellent quality for some people, might not be so for others.
Moreover, in an audio chain, there’s an infinity of elements that can change the sound much more significantly than the topics mentioned here.
For audio aficionados – someone with keen ears, uses excellent hi-fi equipment – parameter differences (such as compression rates) might be more perceptible, depending on the sounds in question.
There’s also the issue that certain sounds with more bass tones, despite not being audible to us – for example, infra-sounds between 4 and 16 Hz – may be perceived tactilely.
Certain (controversial) studies also lead us to believe that ultrasonic frequencies (over 20 kHz), in certain cases can be perceived by our body – not necessarily through the auditory system.
Lastly, our hearing isn’t as developed as our eyesight. Therefore, it’s harder to evaluate audio. Thus, the placebo effect is common when analyzing quality.
For the same reason, the electronics market may in some cases, if taking advantage of the technical evolution of equipment (higher bit depth, sample rate, frequency response values) use this to sell products that in practice, may not make any difference for users.
Now that you know a few important rates to ensure audio quality, make sure you also read our Hotmart tips on types of microphones and capturing audio!
This post was originally published in September 2019 and has since been updated to contain more complete and accurate information.



